- 목차
동기
1월 초중순 어느 날, 내 친구 A로부터 메시지를 받았다.
"혹시 내 목소리를 TTS 보이스로 나오게 하는 프로그램 만들어 줄 수 있어?"라는 내용의 메시지였다.
친구 A는 인터넷 방송을 시작한지 얼마 안되었는데, 본인의 목소리를 직접적으로 방송에 내보내길 원하지 않았다.
하지만 시청자들과의 소통에 많은 불편함을 느꼈고, 처음엔 TTS(Text-To-Speech) 기능으로 소통하는 방법을 생각해냈다.

하지만, 방송에 집중하면서 TTS를 사용하기 위해 텍스트를 타이핑하는 과정이 비효율적이라 생각했다.
결국 앞서 말한 방식으로 작동하는 프로그램을 찾는데 실패했고, 내게 물어보게 된 것이었다.
서비스 서치 하기
TTS(Text-To-Speech) 기능이나 STT(Speech-To-Text) 기능을 제공하는 서비스 기업들이 이미 여럿 존재하기 때문에,
금방 필요한 서비스를 찾을 수 있을 거라 생각했다.
하지만, 우리가 개발하고자 하는 STS(Speech-To-Speech) 기능을 직접적으로 제공하는 서비스를 찾기 어려웠다/
.
이후 지속적인 서치와 문의 결과,
일명 STS(Speech-To-Speech) 기능을 직접적으로 서비스하는 곳은 없었고
STT와 TTS 이 두 기능을 직접 합쳐서 구현해야 한다는 답변을 얻게 되었다.
결국 직접 해당 서비스를 구현해보기로 하고 필요한 기능을 구체화하기 시작했다.
기능 구체화하기
기능 요구사항 중에서 가장 중요한 2가지가 있었다.
첫 번째. 네이버 클로바에서 제공하는 보이스들을 사용할 수 있어야 한다.
두 번째. 입출력 장치를 임의로 조절할 수 있어야 한다.
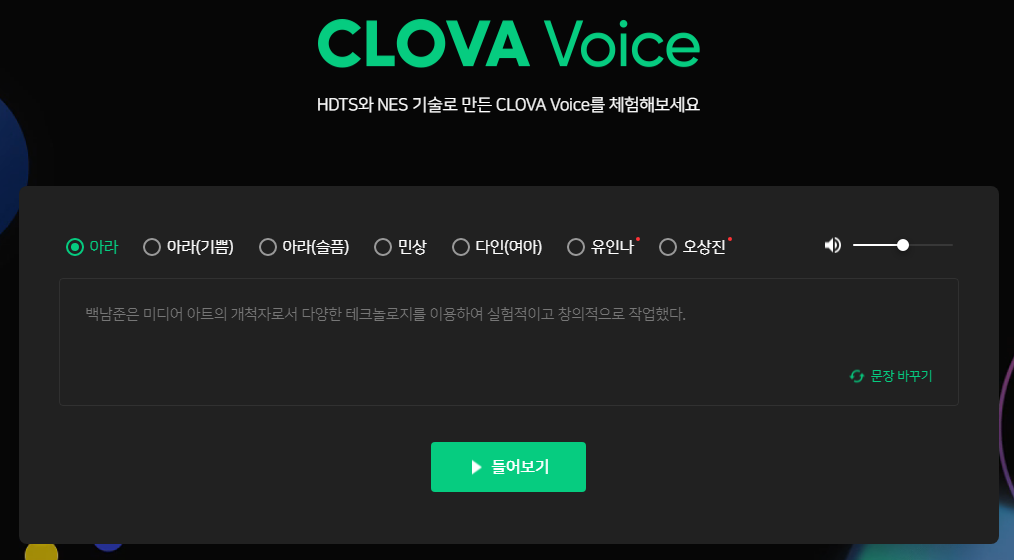
네이버 클로버는 약 40종의 목소리를 제공하고 있는 CLOVA Voice라는 TTS API를 제공하고 있다.
(구글 Speech API에서 TTS 서비스를 무료로 제공하지만, 한 개의 목소리만 제공되고 있다.)
해당 TTS 서비스는 한 달에 약 9만 원 정도의 적지 않은 비용이 소모되지만,
인터넷 방송에 사용될 프로그램이다 보니 목소리의 다양성이 중요도가 높아 그 정도의 가치가 있다 결정해
주요 요구사항에 추가되었다.
그리고, STT 서비스는 마찬가지로 네이버 클로버에서 CLOVA Speech라는 이름으로 유료로 제공되고 있지만,
구글에서 무료로 제공하는 Google Speech API보다 성능이 아쉬워 이를 사용하기로 했다.
(물론, Google Speech API는 한 번에 인식 가능 길이가 최대 1분인 제약이 존재했지만 큰 문제는 아니었다.)
다음으로, 입출력 오디오 장치 선택 기능은 인식할 마이크와 출력할 스피커를 선택할 수 있는 기능으로,
원하는 사운드만을 출력하는 방식으로 진행해야 되는 인터넷 방송 특성상 주요 요구사항에 추가되었다.
구현 과정 알아보기
1. 파이썬을 이용한 방식
처음에 기술 리서치를 하던 중,
STT 기능 구현을 위한 Google Speech API와 TTS 기능 구현을 위한 Naver Clova Voice의 문서를 통해
둘 다 python을 이용한 기능 구현이 가능한 것을 확인했다.
또, 프로그램에 대한 입출력 장치를 변경할 수 있는 기능도
python의 다양한 라이브러리(pyaudio, sounddevice 등)를 이용해 구현할 수 있게끔 제공하고 있었기에
python을 이용해 프로그램으로 만들기 시작했다.
이후 기능 구현은 어느 정도 잘 구현되었지만 곧 몇 가지 문제에 부딪혔다.
첫 번째는 바로 GUI 구현 방식이다.
python에서 GUI를 구현하기 위한 대표적 라이브러리인 pyQt5 사용을 시도했지만,
해당 GUI 툴을 위해 익혀야 될 문법이 너무 많았고, 기능 구현보다 UI에 소모되는 시간이 너무 많아졌다.
물론 pyQt5의 GUI interface를 만들어주는 다양한 툴들도 있었지만,
익혀야 하는 것들만 더 증가하는 느낌이었기에 별다른 도움이 되지 못했다.
두 번째는, 싱글 스레드로 작동하는 파이썬이다.
싱글 스레드 방식으로 수행되는 파이썬 특성상, 함수가 실행되는 동안 다른 함수를 실행하지 못한다.
결국 'STT변환 - TTS변환 - 음성 재생'의 전체 사이클이 종료되어야 새로운 음성을 받아들였는데,
이게 정말 큰 문제였던 게 사용자의 보이스가 TTS 보이스로 변환되고 출력을 마칠 때까지
사용자는 새로운 보이스를 입력할 수 없었다.
결국, python 자체만으로 다양한 시도를 했지만 확실한 해결방법을 찾지 못해 다른 방법을 찾기 시작했다.
2. (현재) 파이썬 + 자바스크립트 방식 (feat. eel)
개인적으로 프론트엔드를 전공하고 있기에 파이썬을 이용해 기능을 구현하고,
HTML과 자바스크립트와 같은 익숙한 웹 개발 언어를 사용해 GUI를 구현할 수 없을까 하는 생각에서
찾게 된 게 바로 eel이었다.
eel은 쉽게 말해 파이썬에서 구현한 메서드를 자바스크립트에서 사용할 수 있게 해주는 라이브러리로,
러닝 커브도 낮아 빠르게 UI와 기능을 구현해나갈 수 있었다.
# python에서 구현한 메서드를
@eel.expose
def sayHello() {
print("Hello World!")
}
// =================
// Javascript에서 가져다 사용할 수 있다.
def greetingInPython() {
eel.sayHello();
}
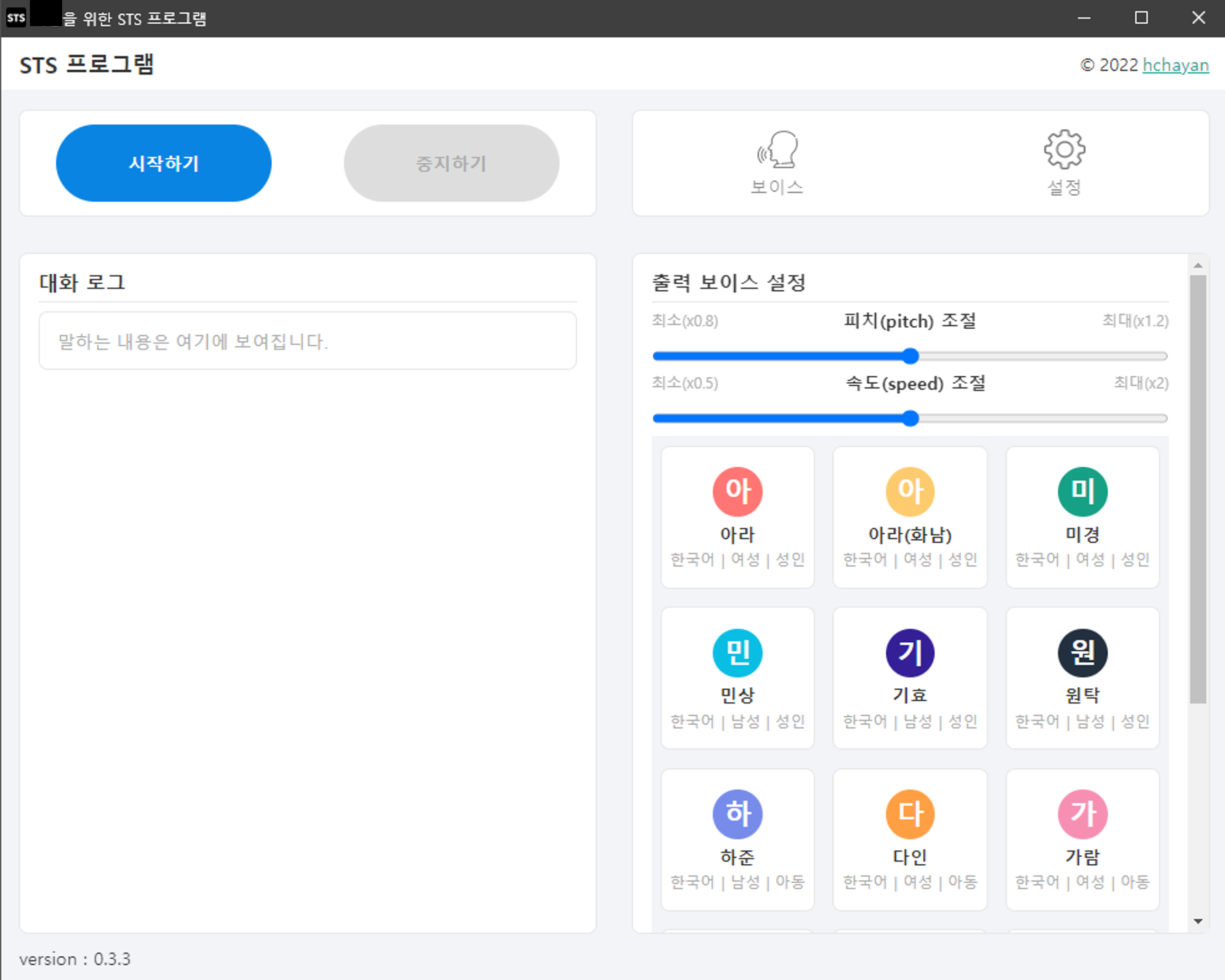
그렇게 빠르게 기능을 구현할 수 있었고, 현재 프로그램의 구조가 바로 이 방식이다.
하지만, 점점 기술에 관한 리서치를 해나가며
조금씩 파이썬을 이용해 구현한 기능을 자바스크립트로 대체할 수 있었다.
예를 들어, STT의 기능을 제공하는 Google Speech API는 Web Speech API라고 MDN에서 제공되고 있었고,
더욱이 기능 시작, 중지, 작동 중에 해당되는 이벤트 리스너가 존재해 보다 고도화된 기능을 구현할 수 있었다.
3. (목표) 웹 페이지를 이용한 방식
앞서 본, 2번 과정을 통해 프로그램이 동작하는 과정으로 프로젝트의 구현은 일단락되었다.
하지만, 여전히 eel를 이용해 파이썬과 자바스크립트 간 기능을 주고받는 블랙박스의 과정이 존재해 아쉬웠고,
자바스크립트만으로 기능을 구현할 수 있는지 여부를 추가적으로 알아보기 시작했다.

사실 이 방식으로 프로젝트를 구현하는 방식을 프로젝트 최초에 고려했었다.
하지만 당시에 자바스크립트만으로 구현에 어려울 거 같았던 몇 가지 기능들이 존재해 포기했었다.
(기한이 한정되어있어 빠르게 프로그램을 만드는 게 중요했다)
우선 TTS 보이스를 재생하는 방식이 문제였다.
Naver CLOVA Voice의 TTS는 주어진 텍스트에 대한 음성 데이터를 mp3나 wav 파일로 반환을 해준다.
그래서 기능을 구현할 때, 이 음성 데이터 파일을 로컬 저장소에 저장 후 재생하는 방식으로 진행되어야 합니다만,
client-side에선 fs를 이용한 파일 시스템 조작이 불가능해, 다른 외부 라이브러리를 사용해야 했다.
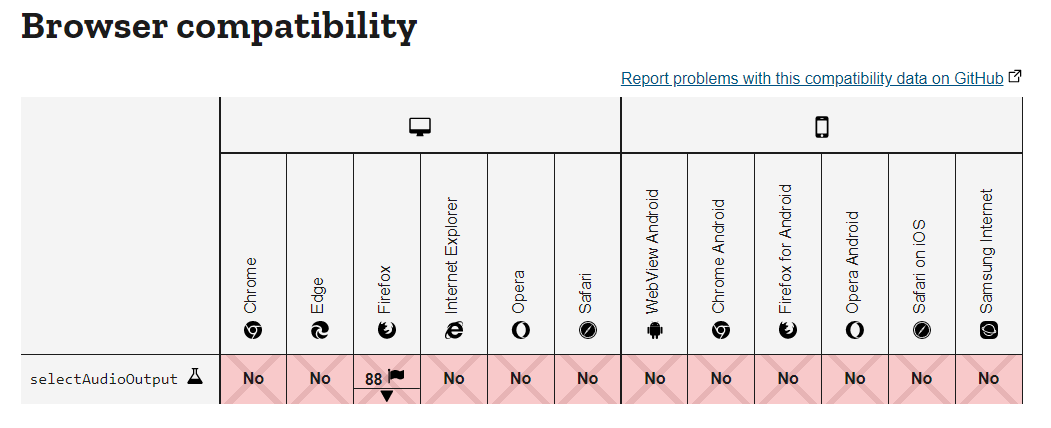
두번짼, 입출력 장치 설정 문제였다.
웹으로 돌아가는 프로그램에서 음성 출력 장치를 선택 가능 여부가 불투명했고,
MediaDevies.selectAudioOutput()이라는 Web API가 있어 알아보았지만 브라우저 호환성이 좋지 않았다.
하지만, 이후 selectAudioOutput를 대체하는 setSinkId와 같은 Web API를 알게 되었고,
TTS 보이스를 저장하고 재생하는 파일 시스템 조작 또한, Express node server를 별도로 두면
충분히 python을 대체 가능하다 보아 시도해보고 있다.

기능 소개
1. 입력한 사용자의 목소리를 TTS 목소리로 변환해 출력해준다.
마이크로 입력한 목소리가 TTS 보이스로 변환되어 출력된다.
TTS 보이스가 출력 중일 때 마이크로 입력한 목소리도 순서대로 출력된다.
(입력에 사용한 목소리는 필자의 목소리이다)
2. 입력한 사용자 목소리의 텍스트 변환 값을 실시간 확인이 가능하다.
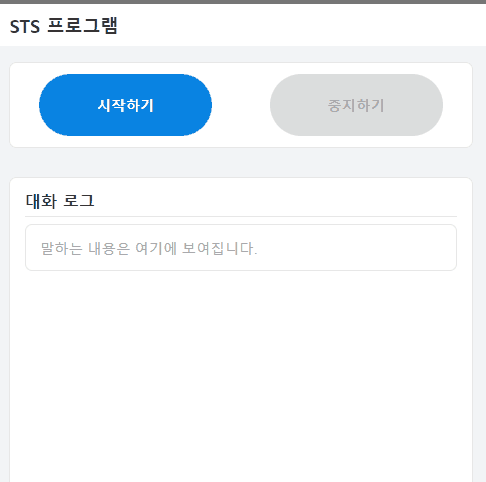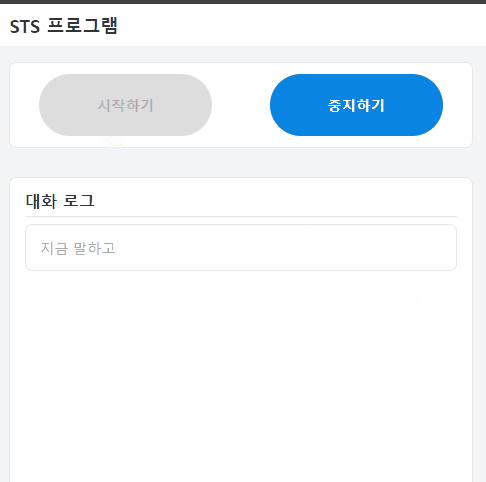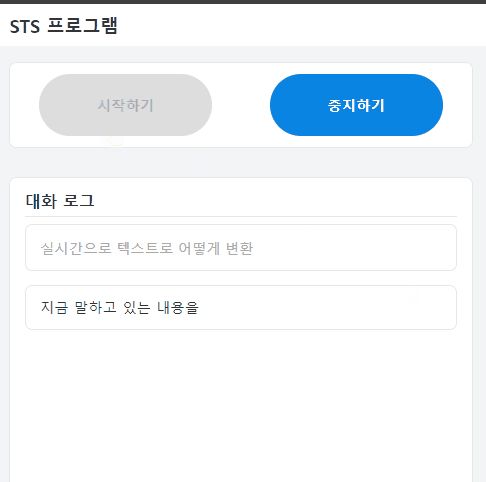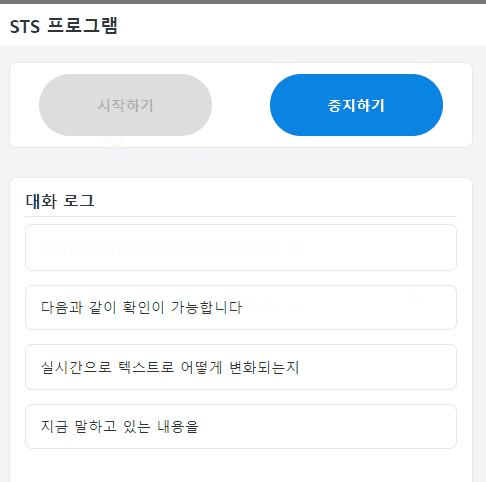
사용자는 자신의 목소리가 어떻게 변환되어 출력될 것인지 텍스트를 확인할 수 있다.
STT기능의 완벽하지 않기에 의도와 다른 말로 인식을 하더라도 사용자가 이를 바로 인지할 수 있다.
3. 클로바 보이스(TTS)에서 제공하는 보이스를 선택해 출력할 수 있다.
프로그램을 중지 후 시작할 필요 없이 클로바 보이스에서 제공하는 다양한 보이스를 선택해 출력할 수 있다.
또한, TTS 보이스의 피치와 속도도 조절해 출력할 수 있다.
4. 사용자의 입출력 장치를 변경할 수 있다.

해당 기능을 이용해 출력장치를 오디오 인터페이스로 선택하면,
OBS와 같은 인터넷 방송 프로그램을 통해 선택적으로 출력할 수 있다.
후기
약 1~2주 정도 사이드 프로젝트 개념으로 짧은 기간 동안 구현한 프로젝트이었다.
우선 기능 구현 방식에 있어,
지금 보면 충분히 노드를 이용해 자바스크립트만으로 구현할 수 있을 것 같아
왜 굳이 파이썬을 사용했는지 아쉬움이 많았지만,
초반에 관련 기술들에 대한 지식이 부족해 어쩔 수 없었던 것 같다.
그래도 파이썬과 Web Speech API에 대해 보다 자세히 알게 된 계기가 되었고
원하던 기능 및 성능을 내고 있기에 어느 정도 만족하고 있다.
무엇보다 의뢰했던 친구가 해당 프로그램에 만족하고 충분히 잘 사용하고 있는 모습이 가장 만족스러웠다.
일단 글은 여기서 마무리하고,
이후 해당 프로그램의 메이저 업데이트가 있거나 목표하는 노드로의 완전한 이식이 완료되면
한 번 더 글을 작성해보려 한다.